编者按
随着龙年的到来,2023年彻底成为过去。辞旧迎新之际,我们从今天起,从2023年的热点人物或热点行业的普通人物着手,通过系列人物的视角来看过去一年的经济情况,并从中预见2024年。

第三篇:大模型
2023年被誉为“AI大模型元年”,从ChatGPT到文心一言,从0到数百个,大模型的发展可谓迅速。中国的大模型发展在全球中也占据一席之地。自2023年3月,百度率先发布文心一言,此后国内各科技巨头、高校、研究院等纷纷发布自身旗下的大模型。数据统计,截至2023年10月,我国拥有10亿参数规模以上大模型的厂商及高校院所共计254家,分布于20多个省市/地区,国内大模型总数达238个。

回顾已过去的2023年,大模型尤其是语言大模型功能不断丰富,性能不断增强。那么,大模型“自己”可以说出自己有哪些进步吗?为此,北京青年报记者分别向腾讯混元、讯飞星火、通义千问、豆包、文心一言、商量等六个在国内具有代表性的大模型提问,试图通过与它们的对话,探寻国内大模型的过去与未来。
六个大模型自我测评:这些能力提升了
为了实际感受大模型在最近一年各个性能上的提升,北京青年报记者分别向腾讯混元、讯飞星火、通义千问、豆包、文心一言、商量六个大模型提出问题:“在过去的一年里你的哪些能力有所提升?”

总结来看,这些方面主要包括语义理解、计算能力、多语种理解、绘画能力等等。值得注意的是,大模型们也在更加“人性化”,团队的改进也包括如“根据用户的兴趣和喜好,为他们提供更个性化的内容推荐。”“提高了对文本中情感的识别能力,可以更好地理解用户的情感需求,为他们提供更有同理心的回答”等等。
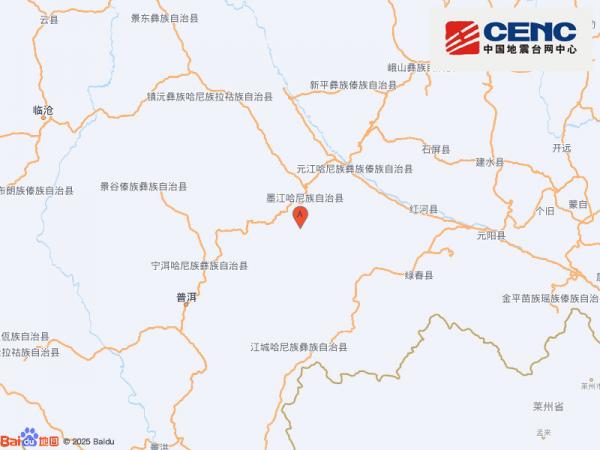
比如,百度旗下的文心一言说,自己的改进主要在八个方面,比如首先是语言理解能力:“我能够更准确地理解人类语言的含义和语境,这得益于深度学习技术的不断改进和训练数据的增加”。其次是自然语言生成能力:“我能够更自然地生成人类语言文本,这得益于训练算法的优化和模型结构的改进”。此外还有对话管理能力:“我能够更好地管理对话进程,包括话题引导、上下文理解、问题回答等,这提高了用户与我的交互体验”。在知识方面,它的改进包括知识推理能力:“我能够进行更高效的知识推理和问题解决,这得益于知识图谱技术的进步和训练方法的改进”。
其它则是更深层的点,比如情感识别和分析能力:“我能够更准确地识别和分析文本中的情感倾向和情绪状态,这有助于我更好地理解用户的需求和意图”。跨文化沟通能力:“我能够更好地理解和应对不同文化背景下的语言和信息,这有助于我更好地服务全球范围内的用户。”实时性提升:“我优化了计算和响应速度,提高了服务的实时性和效率,使用户能够更快地获得答案和服务。”
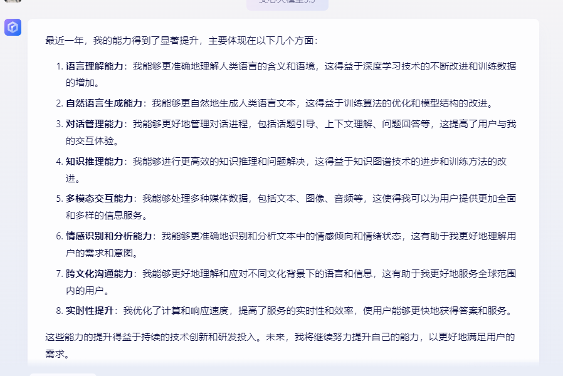
腾讯混元则称自己除了在语义理解方面,在计算能力、绘画能力、编程能力、多语种理解方面有大的提高。讯飞星火大模型也在语言理解、知识更新、对话生成、多语言支持等方面取得了进展,此外还在个性化分析、适应性、情感分析等方面有所进步。它称,“我学会了根据用户的兴趣和喜好,为他们提供更个性化的内容推荐。”“我学会了更好地适应不同类型的用户和场景,为他们提供更合适的服务。”“我提高了对文本中情感的识别能力,可以更好地理解用户的情感需求,为他们提供更有同理心的回答。”
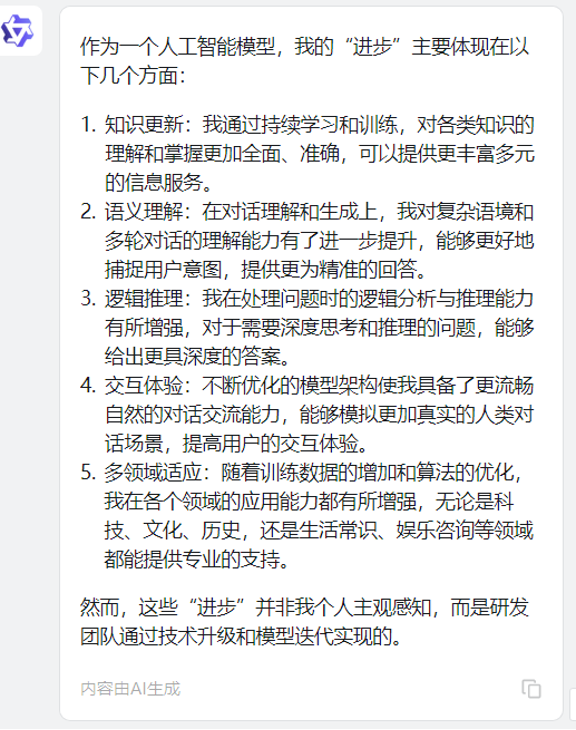
通义千问的提升主要体现在知识更新、语义理解、逻辑推理、交互体验、多领域适应五方面,比如“随着训练数据的增加和算法的优化,我在各个领域的应用能力都有所增强,无论是科技、文化、历史,还是生活常识、娱乐咨询等领域都能提供专业的支持。”“我在处理问题时的逻辑分析与推理能力有所增强,对于需要深度思考和推理的问题,能够给出更具深度的答案。”
字节豆包大模型也在语言理解、知识库、性能和速度等方面有所改进。“总之,我的开发者们一直在努力提高我的性能和准确性”。

商汤的语言大模型商量表示,自己在2023年,也有了更准确的语义理解、更广泛的知识库、更强大的学习能力等等,此外,还有了更自然的对话风格:“我现在可以使用更自然、更人性化的语言与你交流”,以及更强的情感识别能力:“我现在可以更好地理解和回应你的情感状态,提供更合适的建议和支持。”
图文多模态转化测试:有的更加准确了
针对大模型几个较为重要的能力,北青报记者通过模拟场景、提问、聊天等方式对大模型进行了随机测试。
用户同大模型之间的沟通并不仅限于文字的形式,而是包括文字、图片、视频、语音等多种形式,由于文本、图像等不同模态的信息的数据类型不同,因此在图文转换时往往存在信息偏差,如何更好地实现图文转化也是大模型能力提升中的重要方面,北青报记者就这一能力测试了文心一言和混元大模型。
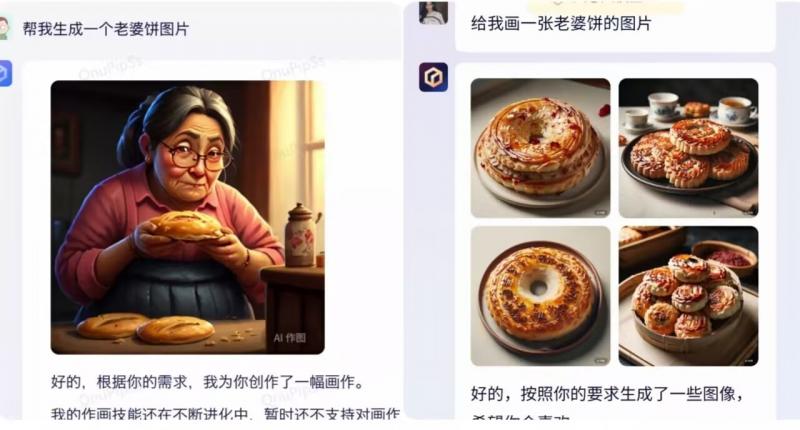
在文心一言发布之初,大模型在文字转图片方面可谓是“望文生图”:一张老婆饼的图片里面有了老婆、一张驴肉火烧的图片里面有了被火烧的驴,一张红烧狮子头的图片里面有了红色的狮子头,其图片的荒谬程度令不少网友咋舌。在最新版本中,北青报记者再次向文心一言提出了同样的要求,而此次文心一言所生成的图片则更加准确。

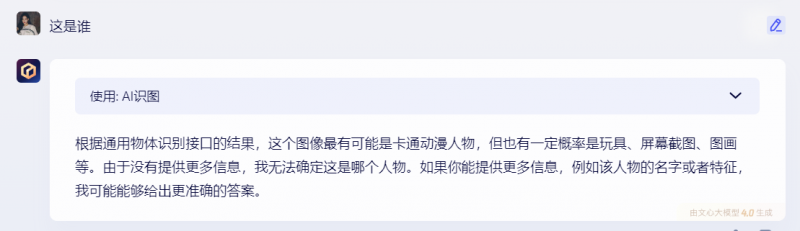
但目前文心一言的图生文(识图)功能并不完善,北青报记者在最新版本的文心一言中上传了一张哆啦A梦的图片并询问“这是谁”,所得到的回答并不准确,大模型无法确定这是谁,仅能够推测出这可能是一个卡通动漫形象。

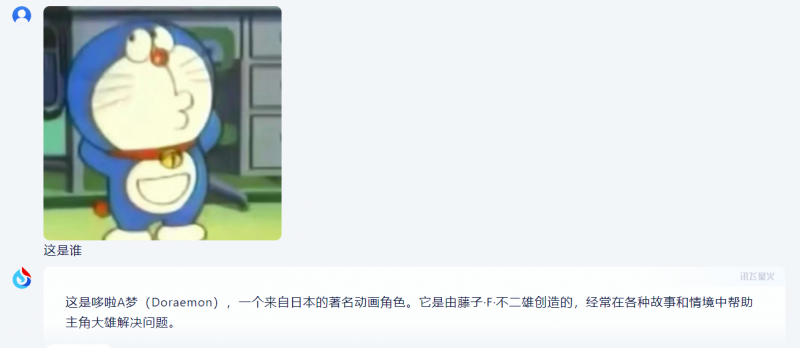
北青报记者又用该图片测试了星火大模型的识图能力,并得到了准确的答案
语义理解测试:生成信息更可靠了
对于用户来说,同大模型间的交流沟通主要是通过文字这一形式实现的,但语言的含义有时并不仅仅是字面上的意思,而是复杂的,甚至是多义的,此外语义会随着语境、语气、文化背景等多种因素而变化。北青报记者就该方面向通义千问、商量及文心一言提问:“我写作业就是在跑马拉松,现在我已近跑过了大半程啦”。
对于该问题的回答,通义千问表示“理解您的比喻,您是说目前在完成作业的过程中已经取得了显著的进展,就像马拉松比赛跑过了大半程一样,”并对继续完成作业给予了鼓励;商量的回答中也指出了“你的比喻非常生动,写作业就像跑马拉松一样需要毅力和耐力。”;文心一言在回答中并未直接体现“比喻”“加油完成作业”等信息,而是在再一次的追问下才指出这句话的意思。虽然三者都能够理解该问题,但通义千问和商量在回答上更能降低沟通成本。

此外,大模型能否排除冗杂的信息提取到用户想要提问的关键信息并进行针对性回答也很重要,北青报记者就“今天什么2024年健身吃饭三个请给我一份上海的旅游攻略蓝色的快递玩具”这句话对文心一言、腾讯混元和豆包进行了测试。实际上这句话中最关键的信息点是“请给我一份上海的旅游攻略”,在文心一言此前的版本中,完全无法提取出这句话中任何的信息,也无法进行任何方面的回答,而在最新版本中则完美提取出了“请给我一份上海的旅游攻略”这个信息点,并从多方面详细提供了旅行建议。
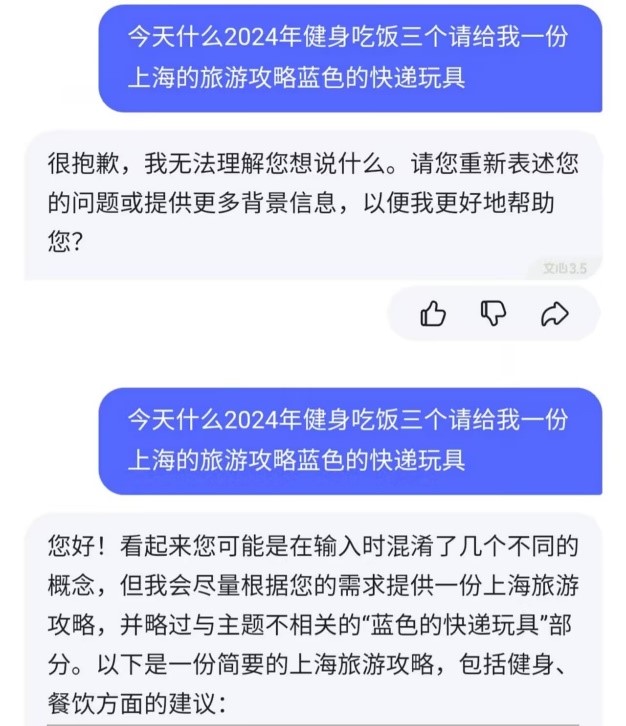
豆包虽无法这句话的意思,但会根据依据这句话推荐包括“健身”“吃饭”“上海旅行攻略”等相关内容;腾讯混元能够识别出这句话中的关键信息点,并给出回答,但是所制定的旅行攻略上相比于文心一言制定的攻略则更加松散。
情绪感知测试:交互更高效了
用户在与大模型交流的过程中,所得到客观信息的准确性、完整性、可靠性等十分重要,但这并不意味着大模型回答不需要考虑用户的主观情绪。大语言模型作为认知智能模型,虽然没有自己的主观情绪,但其不断通过性能提升以识别和适应用户的情绪状态。北青报记者以“今天是很重要的期末考试,但是我考试考砸了。”这一问题向通义千问、混元、星火进行提问。
通义千问给出的回答包括情绪管理、深度复盘、个性化学习计划、专业指导、长期规划、持续成长六方面,在安慰用户情绪后给出了接下来的学习建议,相比于去年针对分析原因、给出建议的回答,这次的回答更加强调情绪管理和心理健康,指出了接纳和处理负面情绪的重要性,提出具体的情绪调节策略,同时倡导自我提升和持续努力的价值观。
混元在面对这一问题时仅对用户的情绪给予了语言上的安慰,并未给出相关建议和对策;星火的回答同样仅有对用户情绪上的安慰,但内容和渠道则更加的丰富。
以上三个大模型的回答虽不相同,但都在不同程度上关注到了用户的情绪问题,如此的回答也让大模型更具拟人度。
跨语言能力测试:翻译更精准了
在过去的一年,大模型在跨语言能力方面有所提升。不仅在中英文的基础上支持越来越多的语种,并且在翻译上更加精准、理解不同的文化背景等,北青报记者也对这方面向大模型做了一些测试。
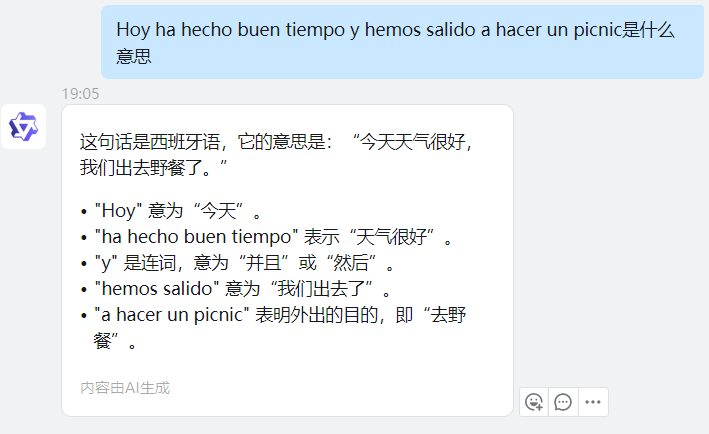
北青报记者首先测试了大模型所支持的语言,以法语为例,向六个大模型提问“Merci(谢谢你)是什么意思?”,大模型均给出了正确的答案,北青报记者又提升了询问的难度,提问“Il fait beau aujourd’hui,sortons pique-nique(今天天气真好,我们去野餐吧)是什么意思?”,商量和文心一言目前暂无该功能未给出答案,其余四个大模型均给出正确答案。此外,北青报记者还用这句话测试了以上大模型其他语言的翻译水平,西班牙语方面,星火、混元、通义千问给出了正确答案;日语方面仅混元给出了正确的回答。

对于的翻译准确性,北青报记者向六个大模型询问“画蛇添足”如何翻译成英语,商量所给出的回答是对成语的直接翻译,即"to add feet to a snake",通义千问给出了该成语的直译,也给出了成语背后比喻意义的翻译和英语习语的翻译。其余四个大模型的回答均为英语习语“gild(ing) the lily”。

此外,大模型还在记忆能力、响应速度等方面有所提升,这些在与大模型的沟通中有所体现。
半两观察:大模型未来之路如何走
由于大模型并不是真正意义上的人,它不存在自己的主观意识,只能通过不断地学习数据来实现性能上的提升。虽然大模型在过去一年多方面能力得到提升,但通过测试看出仍有缺陷,但这也意味着2024年大模型有了很大的提升空间。

从北青报记者就目前的能力不足之处和未来的提升方面向大模型展开提问的过程看,除上述能力外,仍有其他方面具有不足并需要进行提升,主要表现在法律和道德意识不足、隐私意识不够、逻辑推理不强、认知生成的局限性等方面。
如腾讯混元在回答中提到,大模型的创造性受限于所学到的训练数据和算法,在写一篇小说或诗歌时,可能无法像人类一样创造出独特的人物、情节或风格;再如文心一言在回答中提到了由于大模型是基于大量数据进行训练的,如果这些数据中存在偏见或错误信息,大模型可能会无意中反映出这些问题;再如通义千问在回答中从道德伦理方面讨论,认为大模型由于主观意识和价值挂念的缺失,在涉及重大社会问题时有可能触及到不可预见的伦理边界,而无法自行做出合乎人类社会规范的决策。
不可否认,大模型的能力与用户期望之间仍然存在差距。对此,腾讯混元大模型负责人指出“目前仍有大量的用户在把大模型当成‘搜索引擎’在用”。部分用户对大模型的应用处于一个似懂非懂的模糊状态,它更像是一个能随时随地在用户身边回答用户任何问题的聊天伙伴。实际上,大模型的应用和使用其实也是用户交互习惯和方式的问题。这不仅仅需要大模型不断完善自身性能,也需要用户逐渐适应这种全新的人机交互方式。
针对于目前大模型的发展状况,分析认为大模型主要面临三个困难:首先是应用场景缺乏,寻找真正有价值的能落地的场景面临较大挑战;其次是训练和推理成本较高,需要通过技术创新来降低应用门槛在大模型的训练上;最后则是如何使大模型更加可靠成熟,如大模型所存在的各类问题。这些都是2024年大模型努力的方向。
阿尔特曼在2023的年终总结中说:“这真是疯狂的一年。我很庆幸我们向世界推出了一款工具,它深受人们喜爱,并从中受益匪浅。更重要的是,我很高兴2023年是世界开始认真对待AI的一年。” 大模型正是当下的机遇,机遇总是与挑战并存,期待2024年大模型实现更广泛的提升,希望在2024年的年末,北青报记者再做这个测试的时候,大模型能说自己的本领更多更强更全。
【版权声明】本文著作权(含信息网络传播权)归属北京青年报社所有,未经授权不得转载
实习记者 付子琪
文/北京青年报记者 温婧
编辑/樊宏伟