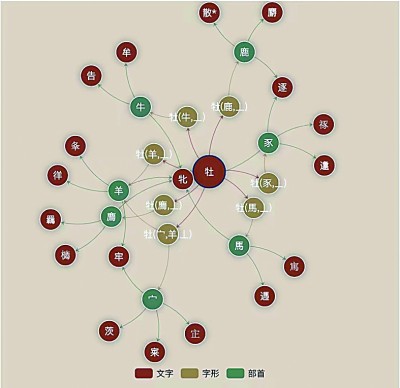
古文字形体系联图谱
人工智能已经参与到人们的生活、工作、学习等诸多方面,科研工作同样如此。古文字专业虽然属于传统学科,却与人工智能技术十分契合。相较于人文学科中的许多专业,古文字考释更为客观,其研究结论具有唯一性,研究过程也遵循一定的规律,在人文学科中最接近自然科学,这符合人工智能技术的工作原理。
那么,人工智能的哪些技术能够辅助古文字研究?之前需要人力完成什么工作?学界目前又做到了什么程度?本文便拟谈谈这些内容。
就古文字考释而言,人工智能可以提供的帮助是多方面的。著名古文字学家唐兰先生曾将古文字的考释方法总结为形体对照法、推勘法、偏旁分析法与历史考证法。人工智能中的图像识别、自然语言处理、知识图谱等技术正可与这几种方法相互对应。
形体对照法是把不同材料中的古文字形体加以比较、对照,利用已识字来考证未释形体。这种方法需要研究者能够熟记大量古文字形体,如此才能把不同材料联系起来。而人工智能识别利用的是深度学习与计算机视觉技术和算法,只要提供足够多的古文字形体来训练模型,就能实现识别功能。记忆方面,数以百万计的文字形体总量,人脑只能记住其中很小的一部分,而智能模型却可以全面覆盖,能力更为强大,识别推荐结果会给专家以有效提示。
推勘法是将出土材料与文献中的记载进行对勘,寻绎文义,进而破解未释形体。随着深度学习技术的使用,尤其是2018年谷歌公司开发的BERT预训练模型在自然语言处理领域的大规模使用,近年来,自然语言信息处理技术发展迅速,在命名实体识别、语义关系等方面有重大提升。经过足够的数据训练,模型能够具有普通人甚至专家一般的能力。举一个通俗易懂的例子,假设“过节了我们煮△▽吃”一句中的“△▽”二形是未释字或残损字。如果要考证这两个形体,经过训练的深度学习模型可以给出备选答案,如“饺子”“汤圆”“粽子”等相符合的词语。因为有“过节”限定,所以“白粥”等普通熬煮食物不会被推荐;因为有“煮”字限定,“月饼”等非熬煮食品不会被推荐。深度学习模型完全能够捕捉语句里面关键字词的文意。对于例子中的这句话,普通人也能给出正确的判断方向。但是如果面对的是古文字材料,情况就不同了,因为多数人对古代汉语并不熟悉,即使专业学者也无法熟记大量的古代语料。所以,我们可以利用出土文献的释文数据和传世古书的记载来训练语言模型,从而在研究过程中利用模型圈定待释字的目标范围,有时甚至能够锁定正确答案,这能给予专家极大的帮助。
偏旁分析法是通过分析、识别偏旁来考释古文字。历史考证法是根据不同时期形体的特征及演变规律来考释古文字。人工智能知识图谱技术与这两种方法相关。知识图谱是描绘实体之间关系的智能网络,能够整合部件、字形、词义几个层次的古文字知识。可以根据文字偏旁系联图谱,从而展示出那些具有相同偏旁的文字及对应形体;知识图谱也具有挖掘文字演变规律的潜力,进而为专家提供帮助。可见,在古文字研究过程中,人工智能技术可以从多个维度为专家提供辅助。
当然,随着战国竹简的公布,古文字的考释方法也发生了变化,通过破解通假关系找到文字所代表的“词”显得尤为重要。这就需要专家做好通假现象标注,经过反复训练使模型具有通假语感。但是面对以往从未出现过的通假用例,模型是无能为力的,所以还需要音韵学家介入,从通假规律等角度进行研究,让模型同时掌握通假条件所需要的“实例”和“规律”。
笔者认为,人工智能与古文字结合可分成三个阶段:第一阶段是人工塑造模型。古文字专家需要整理基础数据,包括资料释文、图版切字、字形拆分、属性标注等等;计算机专家利用这些数据完成功能实现。这一阶段费时费力,最为艰苦。第二阶段是人工智能利用已经实现的技术为专家提供辅助。这有可能是省时省力的资料对勘,有可能是思考方向的积极引导,也有可能是研究结果的智能推荐。此阶段专家也会针对智能技术的不足进行完善。第三个阶段就是人工智能的独立判断,它可以综合以上所有方面给出问题的答案。目前在这一领域的研究,学界似乎尚处在第一阶段。
以上重点谈了人工智能与古文字考释的关系。事实上,人工智能在其他方面也能给研究者提供帮助,如甲骨缀合、甲骨文分组分类、青铜器断代、竹简编联等等。可以预见,将来人工智能技术会在更多方面为古文字研究提供帮助。人们常说,古文字学是一门古老而又年轻的学问。由于人工智能技术的介入,古文字学的“年轻”也体现在研究的方法上,可以与最新的科技相互结合。相信新的研究资料与新的研究方法能让古文字学一直年轻且充满活力。
文并图/李春桃(吉林大学考古学院古籍研究所教授)
编辑/姬源