近日,由生数科技和清华大学联合研发的国内首个纯自研原创视频大模型 Vidu全球首发“主体参照”功能,该功能能够实现对任意主体的一致性生成,让视频生成更加稳定、可控。目前该功能面向全部注册用户免费开放。
Vidu支持图生和文生视频两种能力,于7月底正式上线。所谓“主体参照”,就是允许用户上传任意主体的一张图片,Vidu 就能够锁定该主体的形象,通过描述词任意切换场景,输出主体一致的视频。
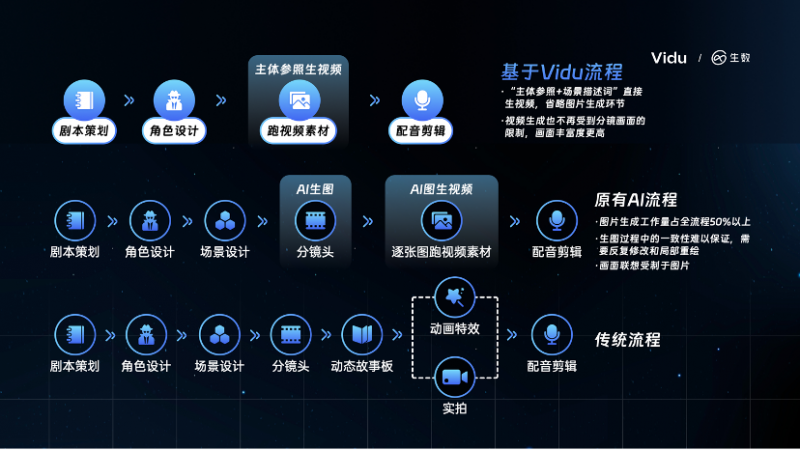
该功能不局限于单一对象,而是面向“任意主体”,无论是人物、动物、商品,还是动漫角色、虚构主体,都能确保其在视频生成中的一致性和可控性,这是视频生成领域的一大创新。Vidu 也是全球首个支持该能力的视频大模型。比如进行人物角色的“主体参照”,无论是真实人物还是虚构角色,Vidu 都能保持其在不同环境中、不同镜头下的形象连贯一致。

例如,输入一张林黛玉的角色照,输入同样的“在现代咖啡厅喝咖啡”的描述,能直观看到,在Vidu “主体参照”功能下,林黛玉的形象在现代场景中得到了完美保留,场景输出也自然而真实。
据了解,此前的视频模型往往难以实现这一点,常常是主体在生成过程中容易崩坏。为了解决这一问题,业界曾尝试采用“先AI生图、再图生视频”的方法,通过AI绘图工具如 Midjourney 生成分镜头画面,先在图片层面保持主体一致,然后再将这些画面转化为视频片段并进行剪辑合成。不过,AI 绘图的一致性并不完美,更重要的是,实际的视频制作过程中涉及众多场景和镜头,导致生图的工作量巨大。而Vidu 的“主体参照”功能彻底改变了这一局面。它摒弃了传统的分镜头画面生成步骤,通过“上传主体图+输入场景描述词”的方式,直接生成视频素材。
Ainimate Lab AI 负责人陈刘芳表示,Vidu与北京电影节 AIGC 短片单元最佳影片得主、Ainimate Lab 合作打造的动画短片《一路向南》,创作团队仅由三人构成:一名导演、一名故事版艺术家和一名 AIGC 技术应用专家,制作周期约为 1 周,而传统流程需要 20 人,包含导演、美术、建模、灯光、渲染等不同“工种”,周期在一个月左右。画面质量接近传统动画制作标准,但成本仅为传统流程的 1/40。
文/北京青年报记者 温婧
编辑/田野