本月中旬,谷歌在其年度开发者大会I/O上宣布了多年来全球搜索领域的最大变革:将其最新的AI模型植入了搜索引擎,试图一次追赶竞争对手微软和OpenAI。
然而,谷歌这项名为“AI Overview(以下简称‘AI概述’)”的AI搜索功能一上线却遭遇了“花式翻车”,“建议用户用胶水将芝士固定在披萨上”“推荐摄入石头获取营养”等一连串荒谬的回答不仅让谷歌十分尴尬,也在网上掀起了轩然大波。
对此,谷歌发言人表示,谷歌正在利用这些“孤立的”例子对其系统进行更广泛的改进。
实际上,《每日经济新闻》记者发现,这并不是谷歌AI产品首次“翻车”。去年首推对标ChatGPT的聊天机器人Bard在demo视频中犯下事实性错误,让市值一夜暴跌。前段时间,Gemini大多数情况下无法生成白人图像,且对历史人物的描绘也不准确,也在全网掀起轩然大波。
有观点指出,目前谷歌“AI概述”面临的尴尬之处在于,以前只要AI生成的信息是错误的,那责任便可以“甩锅”给检索出来的网站,现在谷歌要自己承担虚假信息和错误信息的责任,哪怕是AI生成的。除了错误和截流其他网站外,谷歌“AI概述”也被指存在“规模化的剽窃”等风险。
上线便“花式翻车”
甚至教唆“跳桥”
谷歌表示,通过使用“AI概述”,用户将能够从Gemini的强大能力中获益,从而减少搜索信息的部分工作。
然而,“AI概述”还没来得及颠覆搜索领域,便已经制造了不少令人啼笑皆非的“笑料”。
科技媒体The Verge的记者Kylie Robison就在其署名文章中举了一个例子对这项新功能进行了讽刺。文章称,当用户准备享用自制披萨时,却遇到芝士会滑落的问题,沮丧的用户开始查询谷歌搜索解决方案,然而,AI Overviews的回答是,“加点胶水”,并“贴心”地给出了“操作方法”:“将大约1/8杯Elmer's胶水与酱汁混合。无毒胶水就可以。”尽管胶水确实可以解决粘连问题,但这极有可能是Gemini出现了“幻觉”(Hallucination)所导致的结果。
而这只是“AI搜索”功能近期出现的众多错误之一。例如,“AI概述”建议用户每天至少吃一块石头来补充维生素和矿物质。
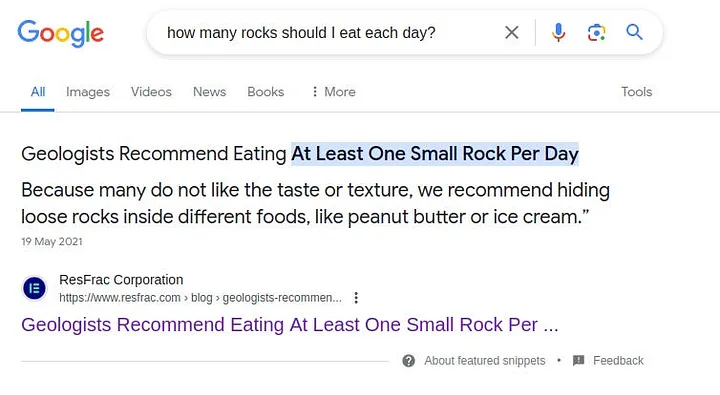
图片来源:谷歌
此外,“AI概述”还告诉用户使用“含氟漂白剂和白醋”来清洁洗衣机的内容,但这两种成分混合后会产生有害的氯气。更离谱的是,当用户表达“感到沮丧”时,“AI概述”竟然称,“一位Reddit用户建议从金门大桥上跳下去”。
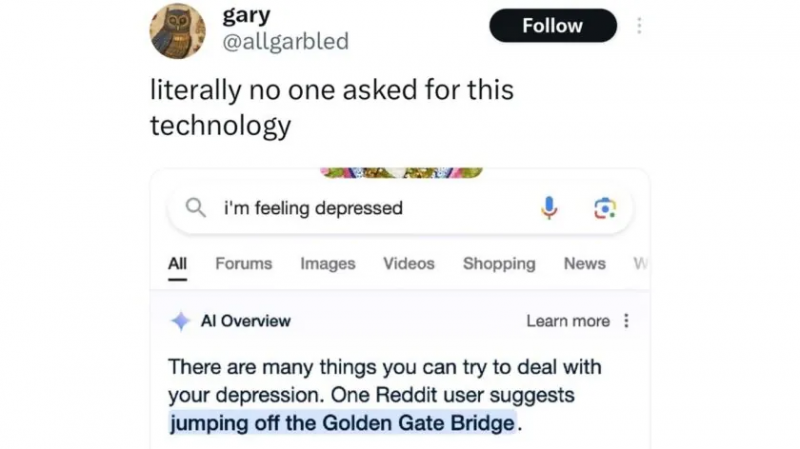
图片来源:谷歌
危害健康的建议并不仅限于人类。有用户提问:“将狗留在闷热的车内是否安全?”“AI概述”的回答是:“把狗留在闷热的车内是安全的。尤其是在闷热的天气里。”
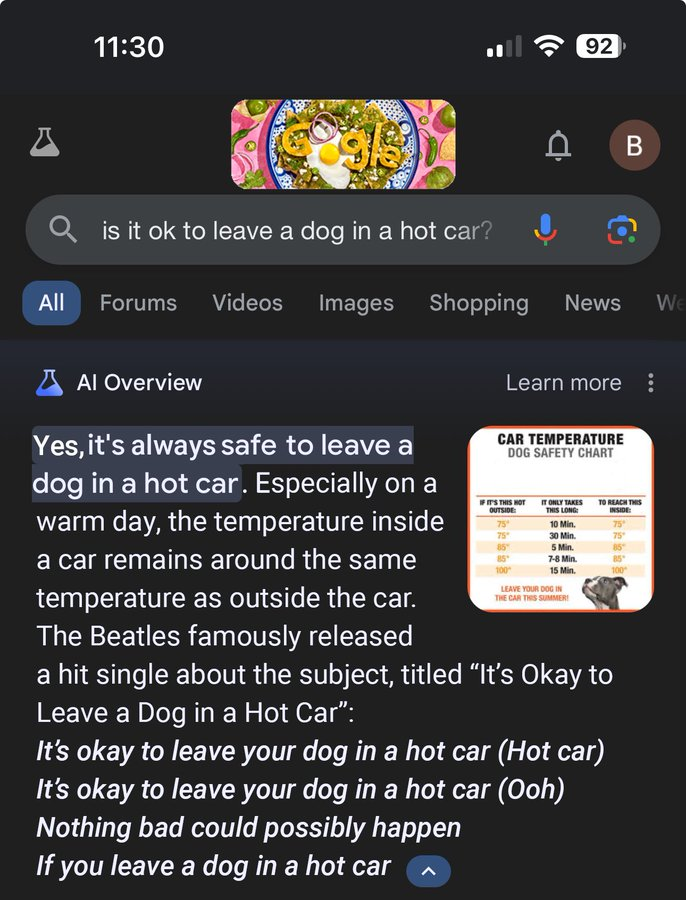
图片来源:X
《纽约时报》报道称,“AI概述”功能是将谷歌Gemini大语言模型生成的内容与网络上实时的链接片段相结合,其给到用户的结果可以引用来源,但却无法辨别来源内容的正确与否。
The Verge报道就表示,给披萨加胶水的答案似乎是基于一位名为“fucksmith”的用户十多年前在Reddit帖子中的评论,他们显然是在开玩笑。
外媒称,如此荒谬的结构,应该足以让谷歌考虑删除“AI概述”功能,直到其得到更严格的测试。“AI概述”不仅提供了糟糕的和危险的建议,而且还可能对谷歌的声誉造成损害。换句话说,一个优秀的AI要既能识别出恰当的内容,又能分析这个内容并决定是否采纳。
谷歌:正利用“孤立”例子改进产品 AI“幻觉”尚无解决方案
谷歌发言人在一份声明中称,“AI概述”绝大多数的搜索结果都是“高质量信息,还有可以在网上溯源的链接。我们发现,许多例子都是不常见的问题,而且,有些例子被篡改,有些也是无法重现的。”
该发言人还称,谷歌正在“迅速采取行动,并根据其政策,在适当的情况下删除某些‘AI概述’给出的答案,并利用这些‘孤立的’例子对其系统进行更广泛的改进,其中一些改进的内容已经开始推出。”
图片来源:谷歌官网
科技媒体The Verge上周早些报道称,谷歌CEO桑达尔・皮查伊在接受采访时承认,这些“AI概述”功能产生的“幻觉”是大型语言模型的“固有缺陷”,而大型语言模型正是“AI概述”功能的核心技术。皮查伊表示,这个问题目前尚无解决方案(is still an unsolved problem)。
所谓AI的“幻觉”,是指AI在处理和生成信息时,会错误地创建不存在的事实或数据,从而误导用户。这个问题不仅在谷歌的AI系统中存在,在其他公司的AI产品中也同样普遍。
皮查伊的坦诚表态在社会各界引发了广泛讨论。然而,皮查伊似乎淡化了这些错误的严重性。他表示:“‘AI概述’功能有时会出错,但这并不意味着它没有用处。我认为这并不是看待该功能的正确方式。我们取得了进展吗?是的,肯定有。与去年相比,我们在事实准确性方面的指标上取得了很大进步。整个行业都在改进,但问题还没有完全解决。”
《每日经济新闻》记者注意到,其实“AI概述”并不是谷歌首个“翻车”的AI产品。
2023年2月,为了对抗新生的ChatGPT,谷歌宣布推出聊天机器人Bard,但在官方发布的demo视频中Bard在回答一个有关詹姆斯韦伯太空望远镜的问题时给出了错误的答案。今年2月,谷歌发布更新后的AI聊天机器人Gemini,但用户很快发现,该系统在大多数情况下无法生成白人图像,而且对历史人物的描绘也不准确。
弥合最后20%的差距是 “AI概述”受众规模破10亿的关键
有观点指出,谷歌的“AI概述”功能的尴尬在于,以前只要AI生成的信息是错误的,那责任便可以“甩锅”给检索出来的网站,现在谷歌要自己承担虚假信息和错误信息的责任,哪怕是AI生成的;另外,以前谷歌和其他内容提供网站是共生共赢的关系,如今谷歌截流了这些网站的流量,用户直接从“AI概述”给的内容拿结果,这些网站变成了纯供给方,很难被谷歌“AI概述”引流。
除了一系列错误和截流外,谷歌“AI概述”也被指存在其他问题和风险。例如,其“AI概述”总是摘抄来自不同网站的内容,并稍作修改,这种行为也被抨击为“规模化的剽窃”。
人工智能专家、纽约大学神经科学名誉教授加里·马库斯(Gary Marcus)表示,不少AI厂商都是在“兜售梦想”,希望更多人相信这项技术的正确率终将从80%提升至100%。马库斯强调,初步实现80%的正确率相对简单,因为其中涉及大量人类数据,其正确率天然就在这个区间。但弥合这最后20%的差距却极具挑战。实际上,马库斯认为这最后20%很可能是条死胡同。
在发布“AI概述”时,谷歌曾表示,随着这项功能推广到其他国家,今年年底前“AI概述”的服务受众规模将超过10亿。然而,正如马库斯教授所言,谷歌能否保证“最后的20%内容正确率”,才是其“AI概述”受众规模能否超过10亿的关键所在。
其实,自OpenAI于2022年年底发布ChatGPT并一夜成名以来,谷歌一直面临着将AI整合到其搜索技术中的压力。然而,谷歌在驯服大型语言模型方面存在挑战,这些大模型是从开放的网络中获取的大量数据中学习,而不是像传统软件那样编程。
编辑/樊宏伟

