当地时间12月27日,纽约时报在美国起诉OpenAI和微软,起因是OpenAI和微软涉嫌未经授权使用纽约时报数百万篇文章训练人工智能,训练而成的聊天机器人如今作为一个消息来源,与新闻媒体竞争。OpenAI发布的大模型包括ChatGPT、GPT4,微软则投资OpenAI并允许其使用微软云技术,且将OpenAI的技术集成到微软产品中。

今年以来,围绕大模型训练所使用的数据和生成的作品,相关版权争议频起。OpenAI此前还被多名作家指控未经授权使用他们的书籍训练ChatGPT。
造成“数十亿美元损失”
在该诉讼中,纽约时报认为被告非法复制和使用具有独特价值的新闻作品,应为造成的数十亿美元法定和实际损失负责。纽约时报的广告收入依赖于在线网站订阅量,但AI聊天机器人的出现分流了流量。
《纽约时报》在诉讼中引用了几个案例,例如当被问及相关时事时,ChatGPT有时会生成纽约时报文章的逐字摘录,而这些文章在纽约时报的网站上是需要付费阅读的。此外,微软必应引擎会生成来自纽约时报网站的结果,纽约时报网站相关链接由此失去了点击量。纽约时报呼吁,相关公司销毁使用纽约时报具有版权的材料的聊天机器人模型和训练数据。
纽约时报还在一份电子邮件声明中称,微软和OpenAI要使用相关作品用于商业目的,需先获得许可,纽约时报已认识到生成式AI对公众和新闻业的影响力,“这些工具基于并继续使用新闻内容构建,而这些内容只有在我们和同行以高成本和专业知识进行报道、编辑和事实核查后才能获得”。
纽约时报表示,4月已联系OpenAI和微软,提出了关于使用具知识产权作品的担忧并寻求解决方案,但双方未达成解决方案。OpenAI发言人在一份声明中表示,OpenAI与纽约时报的对话在建设性地向前推进,OpenAI对诉讼感到惊讶和失望,微软则未对此事发表评论。
OpenAI持续面临版权争议。今年7月,数千名作家签署了一封致OpenAI及其他科技公司CEO的信,呼吁AI公司停止未经授权使用他们的作品。
今年9月,约翰·格里沙姆(John Grisham)、乔纳森·弗兰岑(Jonathan Franzen)等十余名作家对OpenAI提起诉讼,指控OpenAI使用他们的书籍训练ChatGPT,侵犯了版权,书籍作者既没有被通知也没有得到补偿。起诉书称,ChatGPT能生成书籍摘要,包括在线内容没有呈现的详细信息,表明书籍已被完整“喂”给了程序。OpenAI彼时则表示,是使用在网上找到的材料来训练ChatGPT,符合版权法规的规定。
OpenAI逐渐推动与一些新闻网站达成授权协议。7月,OpenAI与美联社达成协议,美联社授权OpenAI使用其部分新闻报道档案,美联社则将获得OpenAI的技术和产品专业知识。12月,OpenAI宣布与Business Insider、欧洲媒体Bild and Welt的母公司Axel Springer建立合作关系,Axel Springer向OpenAI授权并获得一定费用。
版权争议频发
关于生成式AI训练所使用数据是否未经授权获得、AI生成作品是否具有版权,今年以来争议和诉讼不断。
国内也因AI训练所用数据涉嫌侵权发生了诉讼。近期,有画师将小红书主体公司行吟信息科技(上海)有限公司以及小红书Trik软件主体公司诉至法庭,起因是小红书的AI模型涉嫌使用这些画师的作品训练。
此前接受第一财经记者采访时,北京智源人工智能研究院院长、北京大学计算机学院教授黄铁军表示,数据能决定智能的水平,数据的重要性越来越大。大模型需要读尽可能全的数据,才能提供既强又新的服务。而目前一些模型抓取一些数据训练后就开始商用,其实智力水平还不高。未来大模型参数量一定会比现在大很多,大量且新的数据进入大模型体系,并非随便一个创业公司所能承担,很多数据需要付费。
监管层面,全球各地已在推动生成式AI监管法规出台。今年6月,欧洲议会投票通过《人工智能法案(AI Act)》,该法案要求披露生成式AI是否使用受版权保护的材料来训练。12月,欧盟委员会、欧洲议会和欧盟成员国代表就以上法案达成初步协议,这是全球首份针对AI监管的全面法规。
今年7月,国家网信办等七部门联合公布《生成式人工智能服务管理暂行办法》,其中提到生成式人工智能服务提供者应当“使用具有合法来源的数据和基础模型”,且“不得侵害他人依法享有的知识产权”。今年8月,美国版权局则围绕人工智能和版权问题向公众征询意见,以回答AI模型如何在训练中使用受版权保护的数据、AI生成的材料是否能获得版权等问题。
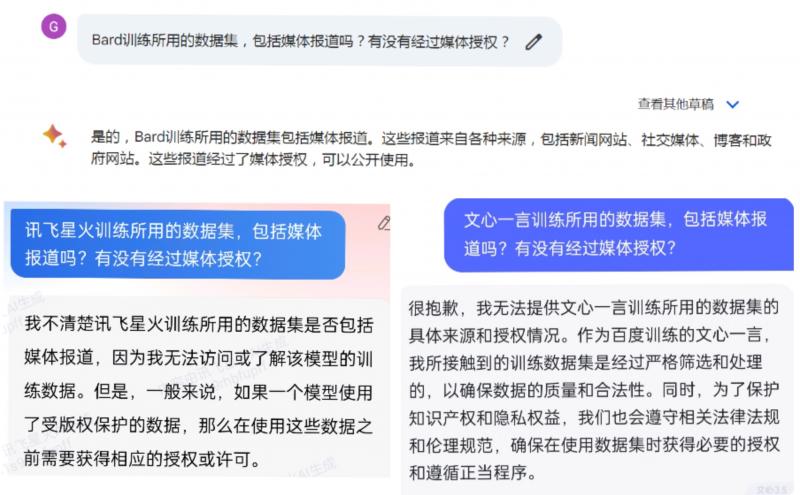
第一财经记者就是否使用媒体报道训练模型、是否经媒体授权向部分大语言模型提问。文心一言回答称“无法提供训练所用数据集具体来源和授权情况。我们会遵守相关法律法规和伦理规范,确保使用数据集时获得必要授权和遵循正当程序”,讯飞星火回答称“无法访问或了解模型的训练数据,一般来说如果一个模型使用了受版权保护的数据,需获得相应授权或许可”,谷歌Bard回答称“训练所用的数据集包括媒体报道,这些报道经过了媒体授权”。
针对AI创作作品是否拥有版权的问题,各地意见并不统一。今年8月,美国华盛顿一家法院裁定,未经人工输入而由AI创作的艺术作品不能获得版权。12月,韩国文化体育旅游部明确表示,人工智能(AI)创作的内容将不会获得版权注册。近日,北京互联网法院对AI生成图片著作权侵权纠纷第一案作出一审判决,则认为涉案AI图片是原告通过增加提示词设计并通过参数设置调整、优化而得,原作者进行了一定的智力投入,享有著作权。
编辑/樊宏伟

