AI领域的版权战事仍在继续,奏响冰与火之歌。本周,一边是OpenAI头号竞争对手的Anthropic被指AI训练侵权遭起诉;另一边则是OpenAI快速推进版权合作,与拥有Vogue等顶级时尚杂志的国际知名出版集团康泰纳仕宣布达成版权合作协议。
版权问题日渐白热化,成为人工智能产业合规最鲜明的课题,新产业与旧秩序缠斗,一边是科技公司攫取高质量训练语料的需求,另一边则是新闻出版机构对自身价值的维护。
“媒体的集体知识产权正受到威胁,我们应该大声要求赔偿。”拥有《华尔街日报》、《泰晤士报》的新闻集团如是说。
通盘来看,目前多数人工智能公司反对训练AI需要版权许可和付费,愿意氪金的是少数。这也是双方之间交锋纠纷的0号源头。
混战中,OpenAI持续推进与新闻出版机构的合作,一方面是为了轻装上阵,摆脱潜在的诉讼官司;另一方面,谈拢的版权合作能更好地支撑具体业务。合作模式主要为给予版权费及相关的利益置换。
这会成为人工智能公司与新闻出版行业之间具有生命力的合作模式吗?眼下双方的合作协议会是终局吗?
OpenAI版权合作商又添大军
8月20日,OpenAI宣布与国际知名出版集团康泰纳仕建立多年合作伙伴关系。这项协议使OpenAI能在ChatGPT 及其搜索引擎 SearchGPT 等人工智能驱动的平台中展示和整合康泰纳仕的内容。
康泰纳仕向OpenAI敞开了内容库,为AI训练提供了养分。同时OpenAI将访问和展示康泰纳仕的信息,用户可以直接通过ChatGPT和SearchGPT来访问这些出版物的信息并与之交互。
康泰纳仕是德国第三大出版公司,旗下包括《Vogue》、《The New Yorker》、《GQ》 等知名杂志。康泰纳仕首席执行官罗杰·林奇(Roger Lynch)表示:“我们与OpenAI的合作可以弥补部分收入,使我们能够继续保护和投资我们的新闻和创意工作。
这项内容合作协议是OpenAI与国际媒体公司达成的最新协议。
康泰纳仕集团的首席执行官罗杰·林奇(Roger Lynch)强调:“这还只是一个开始,我们将继续推进年初开展的工作,为整个行业的公平交易和合作斗争,直到所有开发和部署人工智能的实体都像 OpenAI 一样,认真尊重出版商的权利。”
OpenAI的野心:在AI搜索中分羹
在遭遇几起版权侵权诉讼后,OpenAI一直在积极推进与新闻出版机构的合作。除却此次的康泰纳仕,美联社、Axel Springer、大西洋月刊、Dotdash Meredith、金融时报、LeMonde、新闻集团、Prisa Media、时代周刊、Vox Media 等均已经加入了与OpenAI的合作版权行列。
“我们的使命是将新闻业与人工智能服务更深入地结合起来。”OpenAI称。
放眼整个人工智能领域,愿意投入真金白银来做版权合规、与新闻出版机构洽谈合作的并非常态。
OpenAI此举,一方面是为了轻装上阵。作为人工智能领域塔尖位置的企业,关注度高,诉讼也多。21世纪经济报道梳理发现,在训练数据的版权问题上,美国已有十余起诉讼,其中涉及OpenAI的占了一半。积极争取版权合作,能摆脱潜在的诉讼官司,对一个正在高速发展的企业来讲似乎是明智之举。
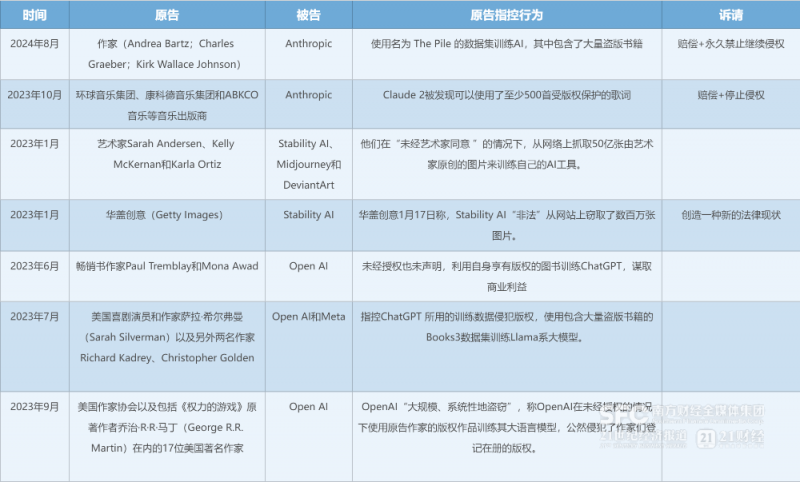
另一方面,谈拢的版权合作能更好地支撑具体业务。
OpenAI与康泰纳仕交易中的一部分就是,在其即将推出的搜索引擎 SearchGPT 产品中使用康泰纳仕的内容。
今年7月,OpenAI 宣布推出其人工智能驱动的搜索引擎 SearchGPT,可以实时访问来自互联网的信息,并且包含信息来源的链接。
此前,不少人把ChatGPT这种聊天机器人当搜索引擎用,但容易出现“不懂装懂”、“一本正经胡说八道”的情况,AI搜索一定程度上可以克服这一点。通常在AI搜索产品中询问相关问题时,给到的回复会以角标的形式在结尾附上参考信源,可点进原链接核查真实性。
这也使得AI搜索也成为AI应用的新战场。非凡产研今年3月的报告显示, AI搜索产品的访问量占据了24.2%的全球市场份额,仅次于AI聊天机器人。
不过,即便标注参考信源也存在版权合规的问题。该赛道领头羊Perplexity就因为人工智能摘要功能而受到非议,出版商声称这是直接剽窃了他们的作品。最近秘塔AI收到了知网28页的侵权告知函,秘塔称搜索产品的“学术”板块仅收录了论文的文献摘要和题录,并未收录文章内容本身,阅读正文需通过来源链接跳转至网站获取。
OpenAI的版权合作,能避免上述的一些版权纠纷。OpenAI称,SearchGPT是与多家新闻合作伙伴共同开发的。OpenAI表示,出版商将拥有一种管理他们在OpenAI搜索功能中呈现方式的方法。他们可以选择不将自己的内容用于训练OpenAI的模型,但仍然可以在搜索结果中出现。
SearchGPT旨在通过在搜索结果中突出显示并链接到出版商,帮助用户与出版商建立联系。响应具有明确的、嵌入式、命名的引用和链接,这样用户就知道信息来自何处,并可以快速通过带有来源链接的侧边栏访问更多结果。
甩掉了版权合规的包袱,OpenAI为了更好铺开AI搜索的业务,去争夺这块应用的阵地。
探路人工智能公司与新闻出版合作模式
21世纪经济报道梳理发现,除了OpenAI,谷歌、Meta也在与新闻出版机构洽谈合作,但是出手远不如OpenAI大方。
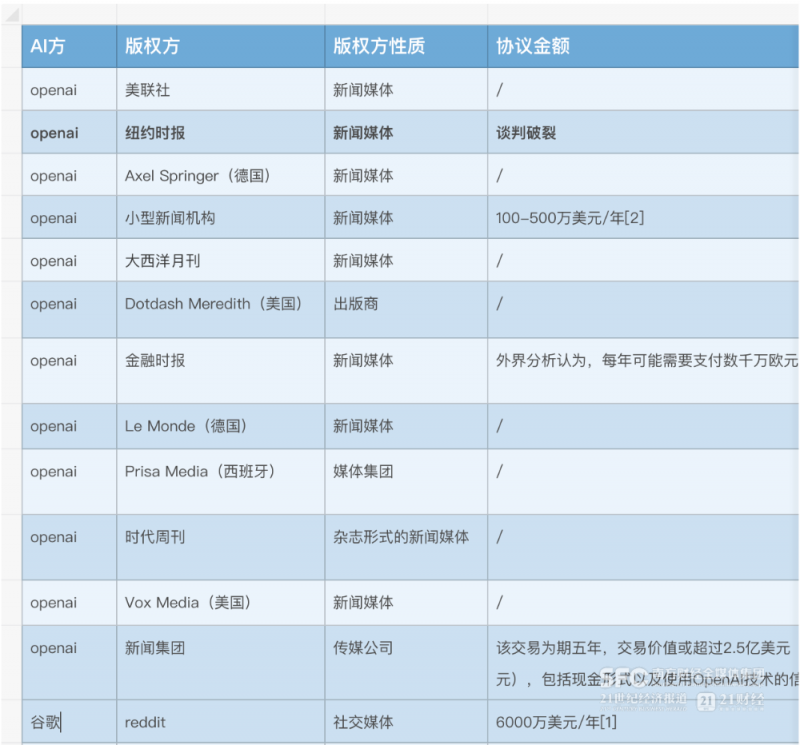

而且,这些钱也并非所愿,多数人工智能公司还在反对训练AI需要版权许可和付费。谷歌在去年回复美国版权局的时候表示,如果拆开看大模型训练过程的每一步——从抓取信息、复制输入到处理分析,只有最初的复制行为能落在版权法范畴中,其他行为不触发版权法。这也是许多大公司认可的观点。
这也涉及到人工智能大模型的技术原理。南财合规科技研究院、21世纪经济报道此前就曾提及过,人工智能时代面临知识“液态化”问题,作品从冰变成了水、甚至蒸汽,难以认定。大模型记住的是统计关系,而不是文本本身。 OpenAI表示,大模型的每串数字(即权重)反映了不同单词在不同情况下的统计关系。当有人发出指令时,大模型调用权重预测下一个词和句子——不会通过数据库重新访问版权作品,也不会直接复制粘贴作品的内容。
“窃书”的举动难以认定,人工智能公司也没有付费的动力。
不过,相关诉讼在增多,新闻出版公司、相关著作权人在积极维权,甚至也有了官方下场,今年4月,谷歌因未妥善使用法国新闻内容训练AI而被罚款2.5亿欧元。
训练数据版权合规在国外逐渐引起重视,OpenAI推进的版权合作一定程度上,是在混战中摸索可行路径。合作模式主要是版权费,补偿内容创作者;以及机构之间的利益置换。
目前通过直接补偿创作者来保障版权的做法主要分为两种:事前补偿:版权人的作品在被采纳为训练数据时获得补偿;事后补偿:通过特定技术追溯 AI 生成内容的训练数据源,并针对性地给予补偿。
不过,事前补偿的技术难度较低,但难以界定合理的补偿额度;事后补偿指通过技术手段对训练数据溯源并进行对应的版权补偿,定价更合理但技术难度尚不成熟。
定价是版权合作中的烫手山芋,《纽约时报》就是“谈崩了”的典型例子。去年4月《纽约时报》开始与OpenAI谈判,但始终没能达成任何付费许可协议。12月27日,《纽约时报》正式将OpenAI告上法庭,指控它们未经许可使报道内容训练AI,要求承担“数十亿美元的法定和实际损失”,标志合作彻底破裂。
所以在很多合作中也有相应的利益置换条款。比如,OpenAI与美联社的合作中,美联社大量的新闻报道将为OpenAI提供训练数据; 美联社也会将OpenAI 的技术整合到新闻业务中。
不过,这是否是人工智能公司与新闻出版行业之间具有生命力的合作模式呢?谈拢合作的新闻出版机构此时吃到的蜜糖,会是以后的砒霜吗?以此次与康泰纳仕的合作来讲,不少反对声音认为,SearchGPT 等人工智能驱动的搜索引擎提供对话式响应而不是传统链接,这些变化可能会影响许多媒体公司赖以赚取收入的搜索流量。
编辑/樊宏伟