5月17日,腾讯混元大模型正式对外发布256k长文模型,并通过腾讯云向广大企业和个人开发者开放。腾讯混元256k模型版本具备处理超过38万字符的超长文本能力。在对话应用场景中,该模型能够“记忆”更多的对话内容,有效避免“忘记”信息等问题。它能够为金融、医疗、教育、出行等行业的专业人士提供强有力的工作支持,显著提高他们的工作效率。

在大模型产品中,处理对话式需求是一项核心功能。但由于长文本处理能力的局限,传统大模型在对话中容易“迷失方向”或出现“记忆缺失”,随着对话长度的增加,遗忘的信息量也随之增多。腾讯混元256k模型针对这一挑战进行了专门优化。目前,腾讯混元大模型已经具备256k的超长上下文理解能力,单次处理字符数超过38万个,在经过严苛的“大海捞针”任务测试后,该模型在长文本处理上的准确率已达到99.99%,在国际上也处于领先地位。
腾讯混元256k的训练集融合了医疗、金融等多个领域的长文本数据、翻译数据和多文档问答等高质量标注数据,这使得模型在实际应用中,尤其是在需要频繁分析和处理大量长文本资料的医疗和金融行业,能够提供更为精准和高效的工作支持。
例如,当将一份央行发布的金融报告输入腾讯混元256k模型时,该模型能够迅速提炼和总结报告的要点,在处理速度和准确性上均达到了令人满意的水平。
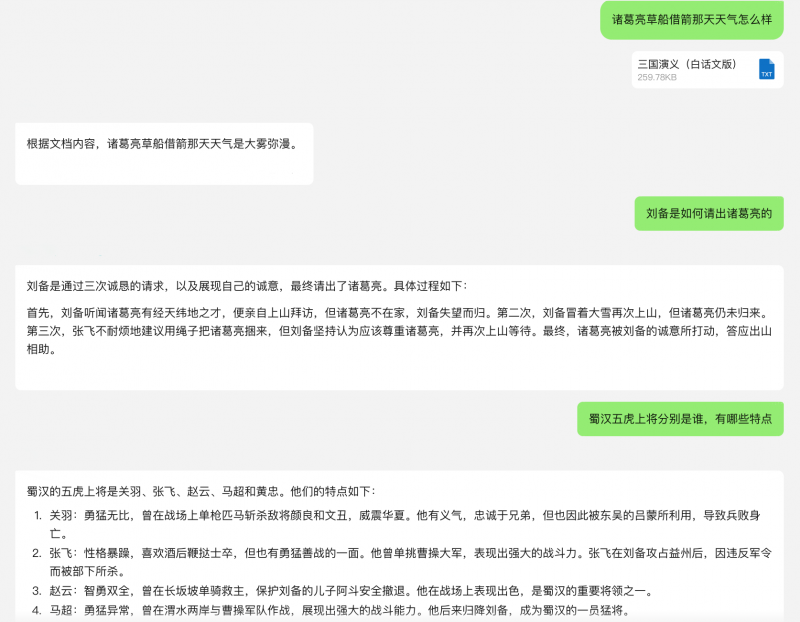
腾讯混元256k在推理性能上进行了深入优化。以《三国演义》的分析为例,腾讯混元256k能够迅速阅读并检索这部数十万字的古典小说,不仅能够准确识别出小说中的关键人物和事件情节,甚至对于天气、角色着装等细节描述也能提供精确的信息。
目前,腾讯混元256k长文模型已经通过腾讯云向广大企业和个人开发者开放,用户可通过hunyuan-standard版本256k长文模型接入。
文/北京青年报记者 温婧
编辑/田野
